蘇寧在智能生態(tài)領域邁出重要一步,集中發(fā)布了涵蓋智能家居、健康管理、影音娛樂等多個場景的12款智能新品。這一系列動作不僅展示了其在消費電子領域的創(chuàng)新實力,更標志著蘇寧正依托其強大的網絡技術服務能力,全面加速物聯網(IoT)生態(tài)的戰(zhàn)略布局。
此次發(fā)布的新品陣容豐富,包括智能空調、掃地機器人、智能門鎖、健康監(jiān)測設備、智能音箱及高清投影儀等。這些產品并非孤立存在,而是通過蘇寧自主研發(fā)的智能中控系統(tǒng)及統(tǒng)一的云平臺實現了深度互聯與數據共享。用戶可以通過一個統(tǒng)一的應用程序或語音助手,便捷地管理家中的各類設備,體驗無縫銜接的智慧生活場景。這背后,正是蘇寧多年來在網絡技術、云計算與大數據領域持續(xù)投入的成果體現。
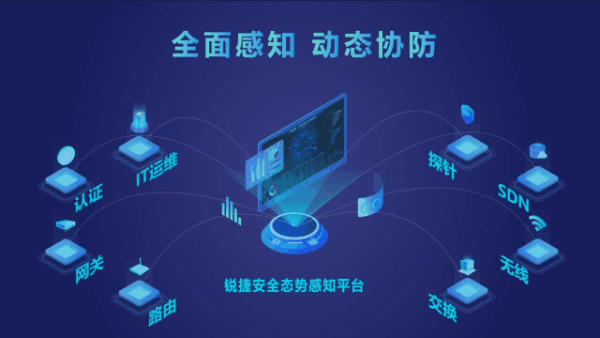
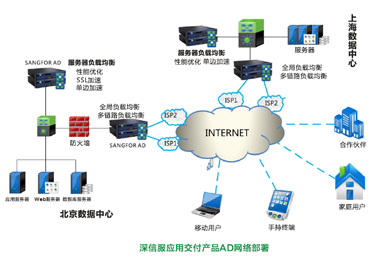
蘇寧的物聯網布局,核心驅動力之一是其扎實的網絡技術服務能力。憑借覆蓋全國的零售、物流與服務體系,蘇寧構建了強大的線下觸點網絡。在線上,其穩(wěn)定的電商平臺、云計算基礎設施以及正在推進的5G和邊緣計算應用,為海量物聯網設備的穩(wěn)定連接、實時數據交互與智能決策提供了可靠保障。此次新品發(fā)布,可以視為將這些技術能力向消費端產品層的一次集中輸出和場景化落地。
從戰(zhàn)略層面看,蘇寧此舉意在構建一個以家庭為中心的智慧生活生態(tài)閉環(huán)。通過智能硬件作為入口,收集用戶數據,再利用其網絡技術進行數據分析與處理,最終通過蘇寧易購等平臺提供個性化的零售與服務推薦。這種“硬件+軟件+服務+內容”的一體化模式,將增強用戶粘性,并為其零售主業(yè)帶來新的增長曲線。
當前,物聯網產業(yè)競爭日趨激烈,各大科技與零售巨頭均在積極圈地。蘇寧選擇此時加碼,并一次性推出多款產品,旨在快速搶占智能家居市場的入口和份額,完善其智慧零售版圖。其優(yōu)勢在于,能將智能產品的銷售、體驗、安裝與售后服務,與其遍布全國的線下門店和物流網絡緊密結合,提供端到端的一體化解決方案,這是純線上廠商難以比擬的。
隨著5G網絡的普及和人工智能技術的深化,物聯網應用將更加廣泛和深入。蘇寧通過本次新品發(fā)布,明確傳遞了其深耕智能生活賽道的決心。其物聯網布局的成敗,關鍵在于能否持續(xù)以領先的網絡技術服務為基石,推動硬件創(chuàng)新、平臺開放與生態(tài)融合,最終為用戶創(chuàng)造真正便捷、智能、互聯的價值體驗。這條路雖挑戰(zhàn)重重,但無疑為蘇寧在未來的科技零售競爭中奠定了重要的基石。