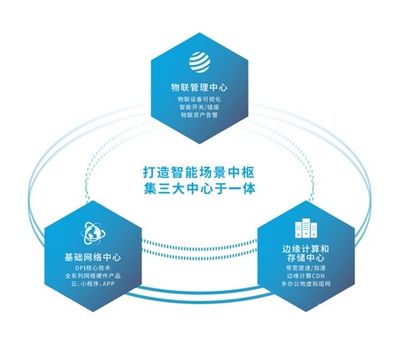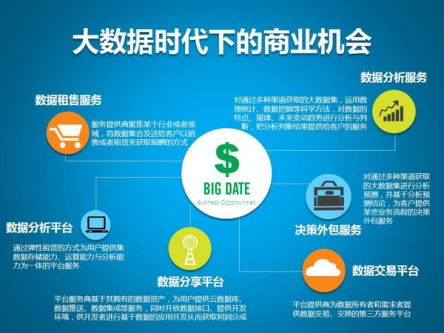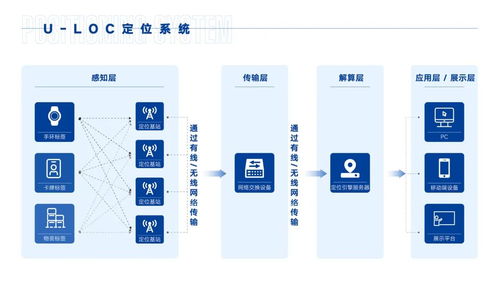
近日,鄭州聯(lián)睿電子科技有限公司宣布將參展iote物聯(lián)網(wǎng)展,展示其創(chuàng)新的融合定位產(chǎn)品及網(wǎng)絡(luò)技術(shù)服務(wù)。作為一家專業(yè)的融合定位產(chǎn)品及服務(wù)提供商,鄭州聯(lián)睿電子科技致力于通過先進(jìn)的物聯(lián)網(wǎng)技術(shù),為行業(yè)客戶提供精準(zhǔn)、可靠的定位解決方案。
在即將到來的iote物聯(lián)網(wǎng)展上,鄭州聯(lián)睿電子科技將重點(diǎn)展出其融合定位系列產(chǎn)品,這些產(chǎn)品結(jié)合了多種定位技術(shù),如UWB(超寬帶)、藍(lán)牙、Wi-Fi和GPS,能夠在復(fù)雜環(huán)境下實(shí)現(xiàn)高精度位置追蹤。公司還將展示配套的網(wǎng)絡(luò)技術(shù)服務(wù),包括云端數(shù)據(jù)管理、實(shí)時(shí)監(jiān)控平臺(tái)和定制化應(yīng)用開發(fā),幫助客戶提升運(yùn)營效率并優(yōu)化資源配置。
鄭州聯(lián)睿電子科技的市場(chǎng)負(fù)責(zé)人表示,隨著物聯(lián)網(wǎng)技術(shù)的快速發(fā)展,融合定位在智能倉儲(chǔ)、智慧城市、工業(yè)自動(dòng)化等領(lǐng)域的應(yīng)用日益廣泛。公司希望通過此次展會(huì),與行業(yè)伙伴深入交流,共同推動(dòng)物聯(lián)網(wǎng)定位技術(shù)的創(chuàng)新與普及。
iote物聯(lián)網(wǎng)展作為全球領(lǐng)先的物聯(lián)網(wǎng)行業(yè)盛會(huì),吸引了眾多科技企業(yè)參與。鄭州聯(lián)睿電子科技的亮相,不僅彰顯了其在融合定位領(lǐng)域的專業(yè)實(shí)力,也為行業(yè)提供了新的技術(shù)視角和商業(yè)合作機(jī)會(huì)。未來,公司計(jì)劃繼續(xù)加大研發(fā)投入,拓展服務(wù)范圍,助力物聯(lián)網(wǎng)生態(tài)系統(tǒng)的完善與發(fā)展。